If you know me or have worked with me, you have almost certainly heard me talk about clean Git history. I am slightly obsessive with rebasing branches, squashing superfluous commits, and keeping the history as clean and easy to read as possible. This isn’t inherently a bad thing! However, I got overconfident this week and it bit me. I’ve been kicking myself for 2+ days at this point (and I’m still not over it) and I figured blogging about it would be both therapeutic (for me) and helpful (for you).
What is Git History and Why is it Important?
Every commit you make into a git repository adds another commit hash into the history of that project.

Looking back through the history of a git repo gives a lot of context to what has been worked on, who did it, why they did it, what changed, and more. The problem with git history is that just like real history, it can get muddled very quickly if you aren’t meticulous in your efforts to catalog and maintain that history.
Here you can see the pull request history in the GovCon repo’s develop branch. Each time we started a feature we branched off of develop, then opened a pull request, then merged the PR back into develop. It is super easy to read the history of this repo. You can literally go back years in the develop branch and see this history.
It involves a bit of effort to maintain, primarily:
rebasing every branch to ensure it’s always starting from the HEAD of the integration branch
avoid squash merges when merging pull requests (to preserve the commit history of the feature branch)
squashing / removing superfluous commits to keep the commits as minimal as possible (note: keeping the full commits by not squash merging AND having a streamlined commit history is a great combination)
rigorous adherence to Git Flow.
The results are well worth the effort, however!
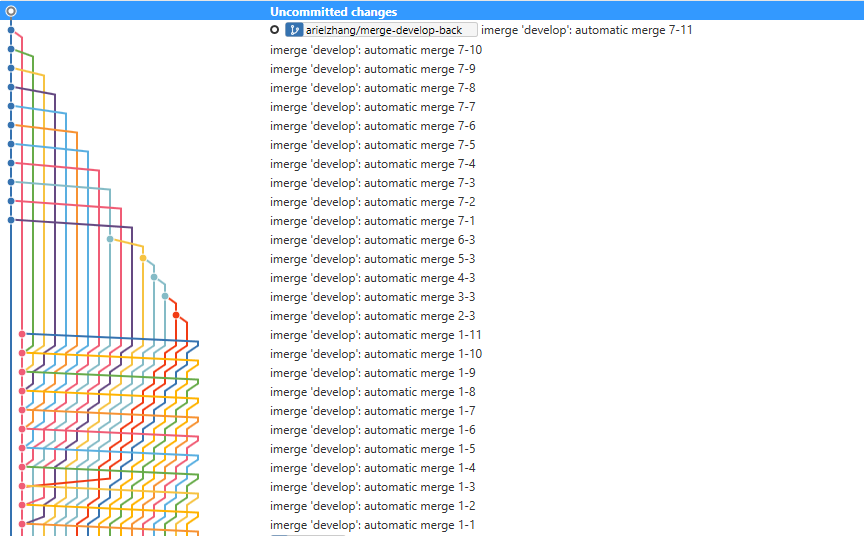
https://stackoverflow.com/questions/45455307/how-merge-git-imerge-final-result-to-target-branch
When you don’t take care to manage your history, you can wind up with a history like this example (which I found on Stack Overflow). What happens if you want to try and go backwards through history? How do you know if a change you made last week got reverted or not? How do you make any sort of sense of those branches? The short answer to all those questions… is that you don’t.
My Stupid Mistake
The thing about putting a lot of effort into keeping your Git history clean and tidy is… sometimes you can go a little overboard. And that’s exactly what I did this week. I got very overconfident. I had a problem that I had been working on for some time, I got a solution (if a messy one) and I started cleaning up my mess. So far, so good!
Where I went wrong though was that I started rewriting my Git history on the fly. I didn’t make a change in a new commit, wait for my continuous integration to run, and then squash. I was amending commits and force pushing as I went. This was working fine… until it wasn’t. And once it wasn’t I had no history to work from. I had a broken state before I started and a broken state where I stood. I didn’t have a trail of commits to walk back wards through.
Don’t be like me! Don’t be overconfident! In this case, if I had done a bunch of stupid, superfluous commits, I could have still gone back later, performed and interactive rebase, and fixed all of the commits after the fact. But because I didn’t do this, as soon as I hit a road bump, I literally had to go back and start completely from scratch. I wasted hours of work. It’s one of the most frustrating things I’ve had happen to me in months and the worst part is I did it to myself. The frustrating part is I know better! But I thought the changes I was making were innocuous. And they were (until they weren’t).
Do it the Right Way

an example of an interactive rebase (git rebase -i <hash>)
So how do you avoid this mistake?
The short of it is, make sure what you’re doing works before you change the history. Ideally, you’ll let the pull requests and tests pass before you cutting things. In other words, be 100% sure that as you’re changing history you are doing it in a way that won’t bite you. A few general suggestions:
never rewrite history in an integration branch (especially if other people are using it)
be very careful when deleting commits entirely (usually it’s safer to squash them)
know what you are changing / squashing
At the end of the day, being able to take a series of commits and rearrange the order, combine them, amend the previous, etc. are all very useful skills to have. If you haven’t done this before, I’d strongly suggest learning how! But you should also learn when to (and most importantly when not to).
Some of the commands:
git commit --amend
git rebase
git rebase -i <hash>
Warning: interactively rebasing and amending a commit both require editing inside of your terminal. So if you usually execute git commands via a GUI be prepared. Personally, I would recommend changing your global git config to use nano instead of vi or other editors (but obviously, pick your poison). You can do this with:
git config --global core.editor "nano"In Conclusion
As with many tools and practices, keeping a clean git history is powerful and important BUT it can also cause damage to you (or your project). So make sure while you’re taking time and care to cleanup your branches you don’t inadvertently wipe away work (or your safety line back). In your efforts to keep things clean you may clean so well that you scour away the very work you need git to preserve.
Related Content


What happens with composer patches silently fail? This article covers a couple common scenarios and how to resolve them.